flink kafka 流数据时间窗口计算
在开始写代码之前,需要先了解一下 flink 流计算中关于时间字段的概念 :https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/event_time.html 此处做简单说明。
Event Time / Processing Time / Ingestion Time
在 flink 流式处理中,针对输入数据,针对时间的处理有三种概念:
- 事件时间 事件产生的时间,即在数据产生时的时间戳
- 处理时间 处理相应操作的机器时间
- 摄入时间 数据进入flink的时间
flink 默认为 处理时间,如果想用时间时间,则需要开启:
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
see.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);Watermarks 水印
关于水印,官方的是这样介绍的:
A stream processor that supports event time needs a way to measure the progress of event time. For example, a window operator that builds hourly windows needs to be notified when event time has passed beyond the end of an hour, so that the operator can close the window in progress.
大意是在支持事件时间的流式处理中,每个计算窗口,比如按小时计算时,需要知道什么时候实际时间达到了窗口的计算边界。
水印是 flink 中用来衡量事件时间进度的机制。其作为数据流的一部分,水印携带一个时间戳的值 t,表示事件时间已经达到该水印值 t,并且没有再比该值 t 小的时间时间值。

图中为携带水印的事件流,事件按顺序到达,水印则只作为一个分隔标记。对于乱序事件,如下图:
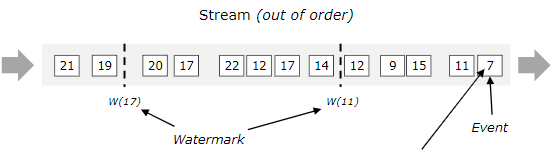
Watermarks are crucial for out-of-order streams, as illustrated below, where the events are not ordered by their timestamps. In general a watermark is a declaration that by that point in the stream, all events up to a certain timestamp should have arrived. Once a watermark reaches an operator, the operator can advance its internal event time clock to the value of the watermark.
这段看的不是太明白,水印对于乱序流很重要,一旦水印时间到达,窗口操作可以内部进行重排序?
demo
下面是一个基于 kafka json table 的流式计算demo,每 5 s 中进行一次计数(已脱敏):
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
see.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
StreamTableEnvironment tableEnv = TableEnvironment.getTableEnvironment(see);
ParameterTool parameterTool = ParameterTool.fromArgs(args);
see.getConfig().setGlobalJobParameters(parameterTool);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", parameterTool.getRequired("bootstrap.servers"));
properties.setProperty("group.id", parameterTool.getRequired("group.id"));
/*FlinkKafkaConsumer011<ObjectNode> flinkKafkaConsumer011 = new FlinkKafkaConsumer011<>(parameterTool.getRequired("topic"), new JSONKeyValueDeserializationSchema(false), properties);
flinkKafkaConsumer011.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<ObjectNode>() {
@Override
public long extractAscendingTimestamp(ObjectNode element) {
return element.get("timestamp").longValue();
}
});*/
KafkaJsonTableSource kafkaJsonTableSource = Kafka011JsonTableSource.builder().forTopic(parameterTool.getRequired("topic")).withKafkaProperties(properties)
.withSchema(TableSchema.builder().field("field1", Types.STRING())
.field("timestamp", Types.SQL_TIMESTAMP()).build())//.forJsonSchema()
.withRowtimeAttribute("timestamp", new ExistingField("timestamp"), new BoundedOutOfOrderTimestamps(30000L)).build();
String sql = parameterTool.getRequired("count.sql");
tableEnv.registerTableSource("test_table", kafkaJsonTableSource);
Table result = tableEnv.sqlQuery(sql);
DataStream<String> resultSet = tableEnv.toRetractStream(result, Row.class).flatMap(new FlatMapFunction<Tuple2<Boolean, Row>, String>() {
@Override
public void flatMap(Tuple2<Boolean, Row> value, Collector<String> out) throws Exception {
Map<String, Object> map = new HashMap<>();
map.put("count", value.f1.getField(0));
map.put("time", value.f1.getField(1));
out.collect(JacksonUtil.toJSon(map));
}
});
FlinkKafkaProducer011<String> myProducer = new FlinkKafkaProducer011<>(
parameterTool.get("log.out.bootstrap.servers", parameterTool.getRequired("bootstrap.servers")),
parameterTool.getRequired("log.out.topic"), // target topic
new SimpleStringSchema());
resultSet.addSink(myProducer);
see.execute(parameterTool.get("job.name", "test") + "_" + +System.currentTimeMillis());
}计算 sql 为:select count(*),TUMBLE_END(\`timestamp\`, INTERVAL '5' SECOND) from test_table group by TUMBLE(\`timestamp\`, INTERVAL '5' SECOND) 目前尝试在流窗口中进行去重计算没有成功,在将客户端和服务端flink 升级到 1.7 后支持
以及:https://medium.com/@mustafaakin/flink-streaming-sql-example-6076c1bc91c1
在使用时间窗口时,要分配事件时间处理逻辑和水印策略:
KafkaTableSource source = Kafka010JsonTableSource.builder()
// ...
.withSchema(TableSchema.builder()
.field("sensorId", Types.LONG())
.field("temp", Types.DOUBLE())
// field "rtime" is of type SQL_TIMESTAMP
.field("rtime", Types.SQL_TIMESTAMP()).build())
.withRowtimeAttribute(
// "rtime" is rowtime attribute
"rtime",
// value of "rtime" is extracted from existing field with same name
new ExistingField("rtime"),
// values of "rtime" are at most out-of-order by 30 seconds
new BoundedOutOfOrderWatermarks(30000L))
.build();rtime :在流数据中要存在这个字段,并且是时间戳字段
BoundedOutOfOrderWatermarks:水印策略,表示流数据最多在 30s 内是乱序的
关于水印策略,接口类为:WatermarkStrategy,有两个可用的实现,1为示例代码中的乱序策略,另外一个 AscendingTimestamps ,表示流数据总是按顺序到达,实际使用需跟情况而定。
总结
1、flink 中支持三种实际策略,即处理时间、事件时间、摄入时间,处理时间为默认选项;
2、在事件时间中,flink 使用水印作为窗口计算边界策略;
3、水印有两种生成策略,即默认顺序到达(AscendingTimestamps ),已经乱序时的可容忍度(BoundedOutOfOrderWatermarks);
4、想要在流式计算时间窗口中支持 count distinct 去重计算,需要将 flink 版本升级到 1.7,flink 从 1.6 开始支持 window 的 count distinct 计算:https://hub.packtpub.com/apache-flink-version-1-6-0-released/ 。
flink sql 文档:https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/sql.html
2018-12-29
1.7 版本中 kafka json table source 类过期了,使用新的 api 构建:
https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connect.html#kafka-connector
tableEnv.connect(new Kafka().version("0.11").topic(parameterTool.getRequired("topic")).properties(properties))
.withSchema(
new Schema()
.field("rowtime", Types.SQL_TIMESTAMP)
.rowtime(new Rowtime()
.timestampsFromField("timestamp")
.watermarksPeriodicBounded(60000)) // optional: declares this field as a event-time attribute
.field("field1", Types.STRING)
).registerTableSource("test_table");同时我还发现,Types 貌似是支持对象列表了,新版的 api 也更加简洁。